2026年4月7日
Gemma4とは?Googleが放つ高性能オープンモデルの特徴・使い方を解説
2026年4月2日にGoogleDeepMindが最新版のオープンモデルとしてGemma4を発表しました。何がすごいのか?どうやってローカルで実行するのか?まで徹底解説します。


2026年4月2日、GoogleはオープンモデルシリーズGemmaの最新版「Gemma 4」をリリースしました。
これまでのGemmaシリーズには商用利用の制限がありましたが、Gemma 4からはApache 2.0ライセンスに変更され、企業・個人を問わず自由に使えるようになりました。
「社内データをクラウドに送りたくない」「APIのコストを抑えながらAIを使い続けたい」という企業・ユーザーにとって、自分のPCやサーバー上でLLMをローカル実行できるGemma 4は、非常に現実的な選択肢です。
この記事では、Gemma 4の主要な新機能・4つのモデルサイズの選び方・Ollamaを使ったローカル実行方法・企業での活用シーンまでを解説します。
Gemma 4とは?Gemma 3からの進化ポイント
Gemma 4は、Google DeepMindが開発するオープンモデルシリーズの第4世代です。
Gemma 4はGemini 3と同じ研究技術をベースに開発されており、「パラメータあたりの知性」で過去最高水準を達成しています。
Gemma 3からの主な進化は以下の3点です。
- MoE(Mixture of Experts)アーキテクチャの導入 26Bモデルに採用された新設計で、推論時に全体の約15%のパラメータのみを使用します。これにより、大規模モデルと同等の品質を、はるかに少ないメモリで実現できます。
- 全モデルのマルチモーダル化 E2B・E4Bを含む全4モデルで、テキスト・画像・動画に加えて音声入力がネイティブ対応になりました。
- Apache 2.0ライセンスへの変更 ユーザー数・利用形態の制限なしに商用利用・改変・再配布が可能になりました。企業がGemma 4をベースに自社サービスを構築したり、ファインチューニング済みモデルを配布したりするハードルが大きく下がっています。
Gemma 4の主要な新機能・特徴
Thinkingモード(思考モード)
Gemma 4の全モデルに共通して搭載された機能です。最終的な回答を出す前に、モデルが内部でステップバイステップの推論プロセスを実行します。数学的な問題や、複数のステップを経て解くべき複雑なタスクで特に効果を発揮します。開発者はシステム命令を通じて、思考の深さや効率を調整することもできます。
拡張マルチモーダル対応
テキストと画像に加え、動画(最大60秒)と音声(最大30秒、E2B・E4Bのみネイティブ)をサポートしています。OCR・手書き文字認識・グラフ読み取り・画面のUI理解など、ビジネス文書に関わる幅広いタスクに対応しています。140以上の言語でのネイティブ学習がなされており、日本語でも高い精度を持ちます。
長いコンテキストウィンドウ
E2B・E4Bは最大128Kトークン、26B MoEと31B Denseは最大256Kトークンのコンテキストに対応しています。長文の社内ドキュメントや、複数の文書をまたいだ情報の照合・要約といった用途に有効です。
Apache 2.0ライセンス
GemmaシリーズとしてはじめてApache 2.0ライセンスで公開されました。ユーザー数や利用形態の制限がなく、自社サービスへの組み込み・改変・再配布がすべて自由です。スタートアップから大企業まで、オープンモデルを事業に取り込みやすい環境が整いました。
より詳細な情報が知りたい方はこちらの公式サイトをご覧ください。👇
4つのモデルサイズ比較|現実的な選び方
Gemma 4には用途とハードウェアに応じた4つのモデルが用意されています。
モデル | 必要メモリ(Q4目安) | 想定環境 | 主な特徴 |
|---|---|---|---|
E2B | 約3〜4GB | スマートフォン・Raspberry Pi | 超軽量・音声対応 |
E4B | 約5〜6GB | MacBook・普通のPC | ← まずはここから |
26B MoE | 約10〜14GB | VRAM16gb以上搭載のGPU搭載PC | 速度と品質のバランス |
31B Dense | 約20〜24GB | ワークステーション | 最高品質・研究用途 |
一般的なパソコンで快適に動かすならE4B/E2B
E4BはQ4量子化で約5〜6GBのメモリに収まります。MシリーズのMacBookはRAMが16GB以上搭載されているモデルが一般的なため、追加の設備投資なしにほぼそのまま動かせます。WindowsのノートPCでも、8GB以上のRAMがあればCPUのみで動作させることが可能です(ただし速度は5〜8トークン/秒程度に低下します)。
しかし常用のパソコンとなるとOSや普段使用するブラウザなどのアプリケーションとRAMを共有して使用するので動作が不安定になったり遅くなったりする可能性があります。
動作が重い場合はLLMの性能は下がりますが、より軽量なE2Bを使用してみることもおすすめです。
E4Bをローカルで動かす方法(Ollama編)
Ollamaとは?
Ollamaとは無料でパソコン上でLLMを簡単に実行できるソフトウェアです。
今回はGemma4をパソコン上で実行する方法としてOllamaを用いた手法を紹介します。
Step1:OllamaのダウンロードページからOllamaをダウンロードする
Ollamaのダウンロードページへ移動し、お使いのパソコンに合わせてOllamaをダウンロードしましょう。
筆者はMacを使用しているのでMacOSをクリックし、Download for macOSをクリックします。すると自動でダウンロードされるのでそれを開いてインストールしましょう。
Step2:Ollamaを起動し、モデルを選択する
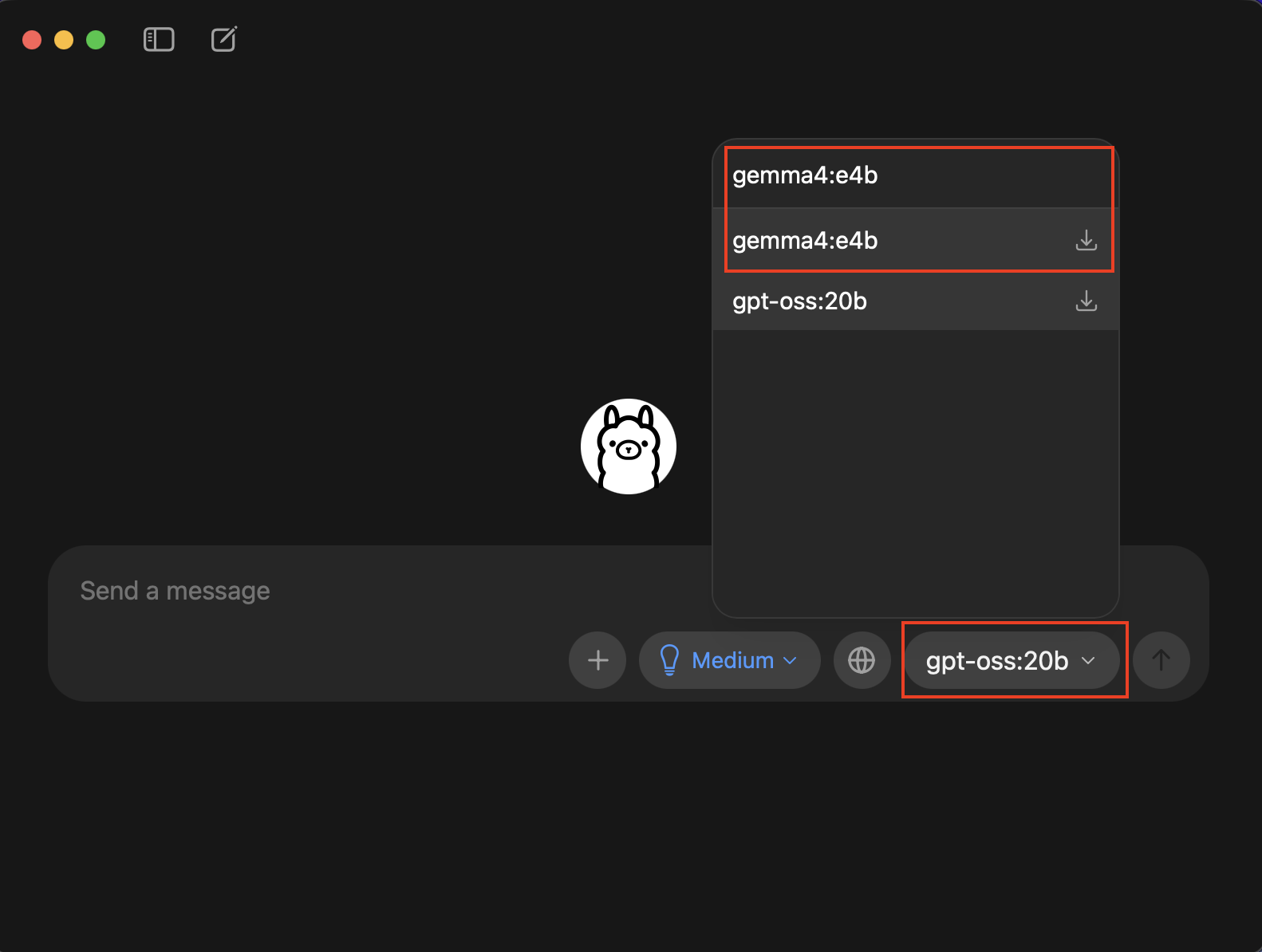
Ollamaを起動しただけではまだモデルがダウンロードできていないので使用することはできません。
画像のように右下のモデル選択から「Gemma4:e4b」と入力し選択します。
Step3:実際に会話を始める
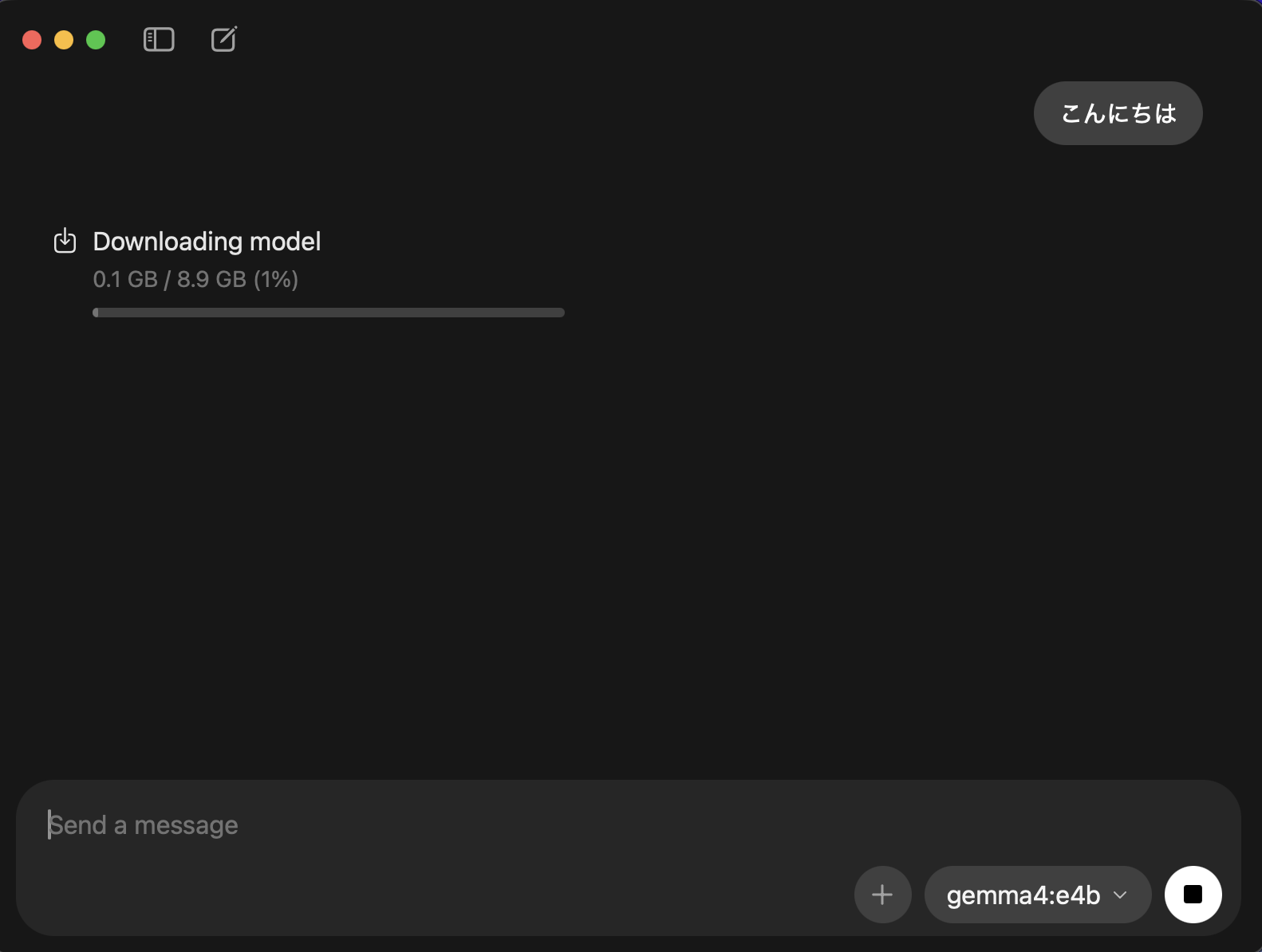
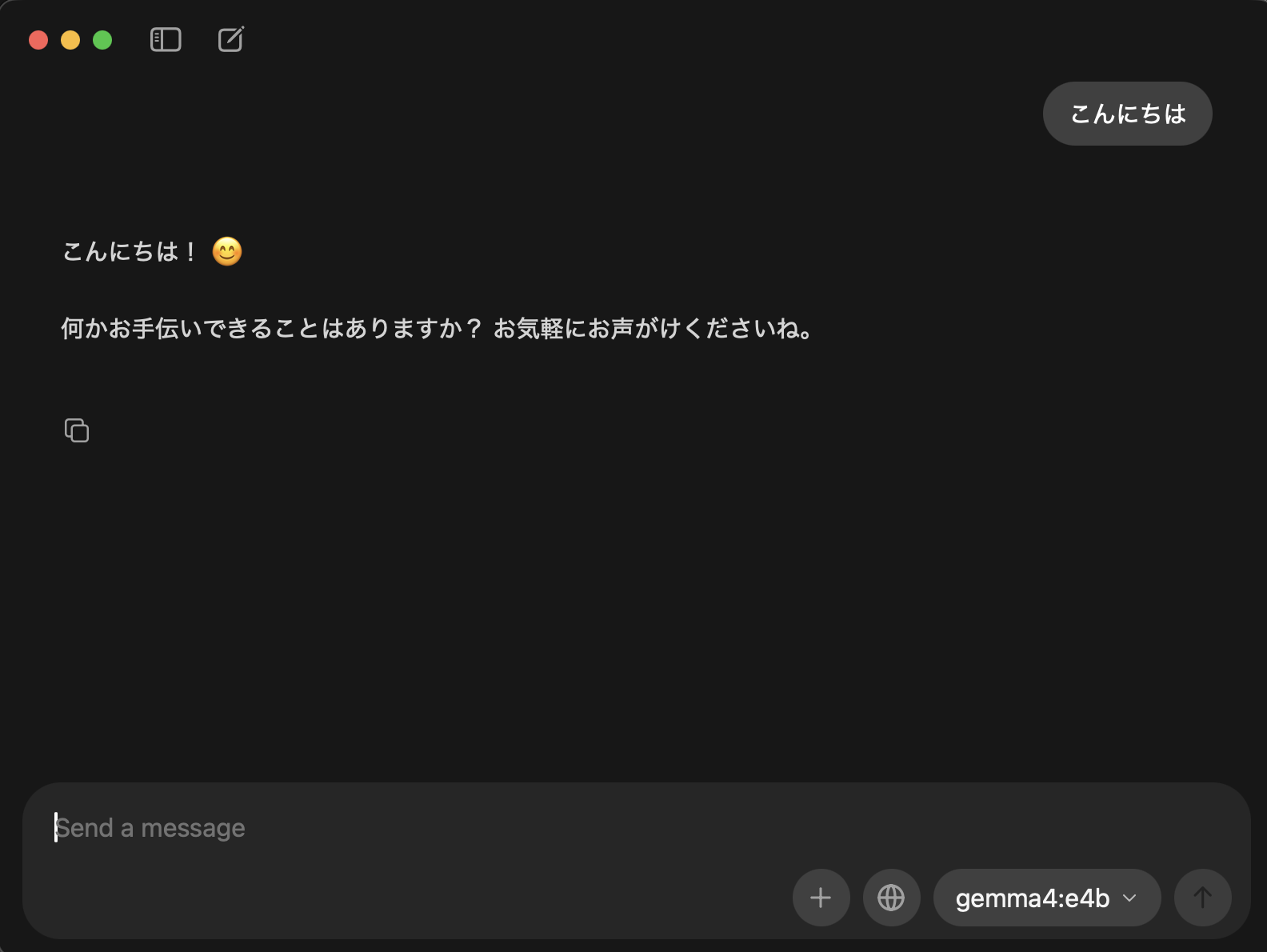
モデル選択後初回のみ指定したモデルのダウンロードが開始されます。
ダウンロードが完了すると2枚目の画像のように回答を得ることができました。
企業・ビジネスでの活用シーン
セキュアな社内AI環境の構築
ローカルLLMの最大のメリットは、社内文書や顧客データをクラウドへ一切送信せずにAI処理を完結できる点です。
Gemma 4はApache 2.0ライセンスで提供されているため、自社サーバーやオンプレミス環境への導入も制限なく行えます。
情報漏洩リスクを抑えながら生成AIを業務活用したい企業にとって、現時点で最も現実的なオープンモデルの選択肢の一つです。
エージェント型ワークフローへの応用
Gemma 4は関数呼び出し(Function Calling)と構造化JSON出力をネイティブにサポートしており、外部のAPIやシステムと連携する自律型エージェントの構築に向いています。多段階の計画が必要な業務フロー(例:問い合わせ内容の分類→社内ナレッジベースの検索→回答の下書き生成)を、一貫したパイプラインとして構築しやすくなっています。
コスト効率の観点
月間100万トークンを超える規模での利用になると、クラウドAPIよりもローカル実行のほうがトータルコストを抑えられるケースが多くなります。モデル自体は無料でダウンロードできるため、かかるコストは主にインフラ(サーバー・GPU・電気代)の費用のみです。
しかしながら、このようなモデルの性能は依然として最新のChatGPTで採用されているモデルやClaudeのモデルなどには及ばないことに注意しておく必要があります。
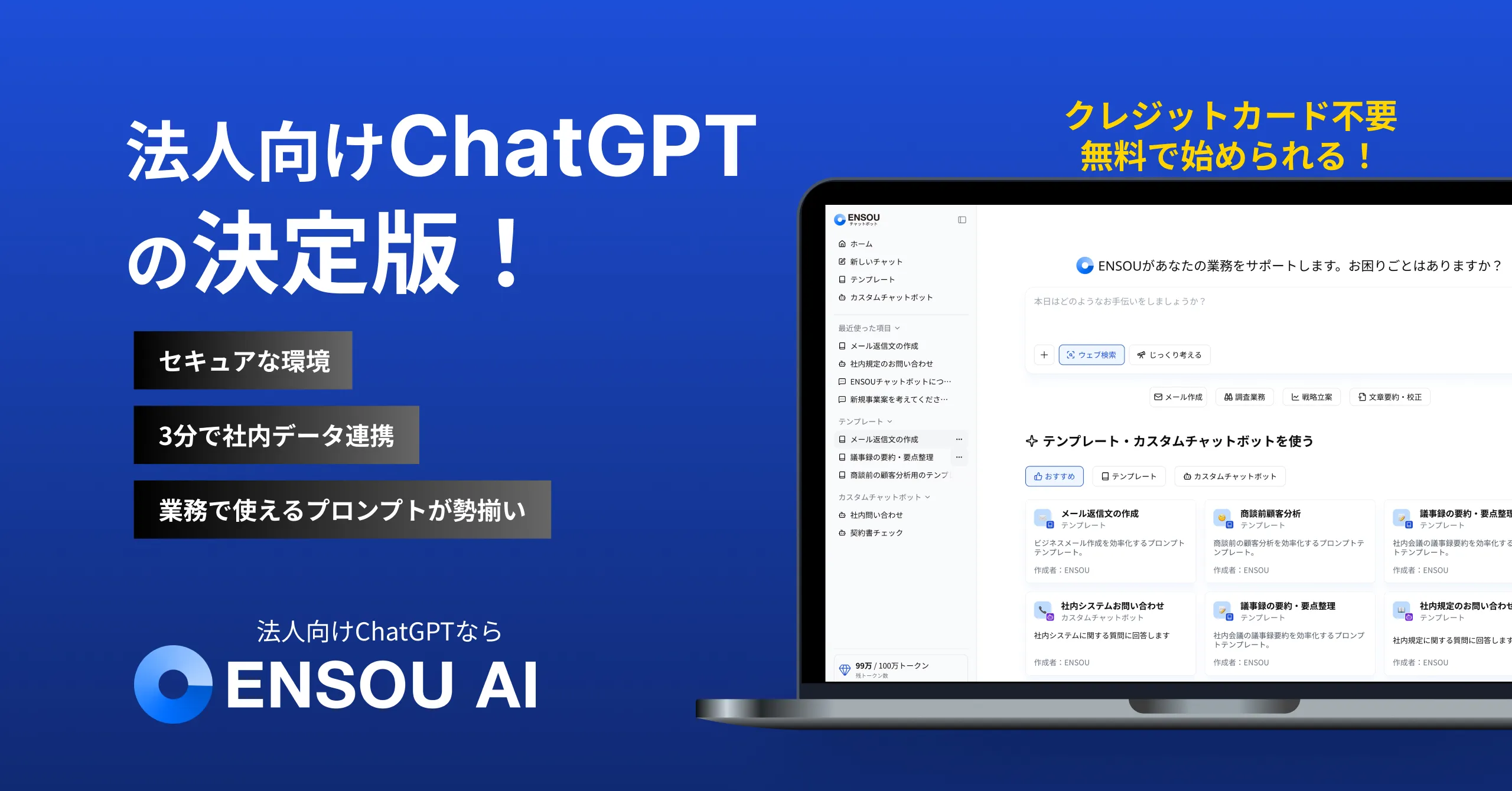
ENSOU AIならコストと性能、セキュアを実現!
ENSOU AIは、生成AIを基盤に、業務を実行するAIエージェント機能までを備えた、強固なセキュリティ環境で安心して利用できる法人向けAIサービスです。
ENSOU AIではGemini,GPTの両方からより最適なモデルを自動選択して処理を行うことが可能です。
無料ですぐに使えるフリープランのご利用開始はこちらから👇
サービス紹介資料をこちらからダウンロードいただけます👇
ご相談、無料トライアルは、以下からお問い合わせください👇
まとめ
Gemma 4は、Googleが提供するオープンモデルとして過去最高水準の性能を持ちながら、Apache 2.0ライセンスで商用利用も自由に使えるモデルファミリーです。全モデルでマルチモーダル対応・Thinkingモード搭載という点も、前世代から大きく進化したポイントです。
まずローカルで試してみるなら、MacBookや一般的なWindowsPCで動くE4BやE2Bがおすすめです。
ローカルで実行するモデルの性能は最新のGPTやGemini,Claudeのモデルと比較するとできることがかなり限られてしまうので、まずは小さく試し本当に実現したいことができるのかを検証してから拡大するのがおすすめです。
あわせて読む
NEW
最新記事
ブログ
Gemma4とは?Googleが放つ高性能オープンモデルの特徴・使い方を解説

ブログ
SharePointで探しているファイルが見つからない?その原因とAIで探し出す方法

ブログ
【2026年版】社内RAGとは?仕組み・導入方法・精度改善まで徹底解説

ブログ
マークダウン(Markdown)とは?ビジネスでAIをもっと使いこなすための基本と活用法

ブログ
RAGとは?その仕組みとRAGの精度を向上させる方法

ブログ