2026年3月3日
Gemini 3.1 Flash-Liteとは?性能・料金を解説
Gemini 3.1 Flash-Liteの性能・料金・活用シーンを公式情報をもとに解説。前世代比45%高速化、入力$0.25/100万トークンの低コストモデルの使いどころがわかります。


Gemini 3.1 Flash-Liteは、Googleが2026年3月3日にパブリックプレビューとして公開した、Geminiモデルファミリーの最新軽量モデルです。
前世代のGemini 2.5 Flashを上回る推論性能を、より低いコストと高い処理速度で実現しており、大量リクエストを処理する法人ユースケースでの活用が見込まれます。
Gemini 3.1 Flash-Liteの概要
Gemini 3.1 Flash-Liteは、Geminiモデルファミリーにおけるコスト効率最優先の軽量モデルです。モデルIDは gemini-3.1-flash-lite-preview で、Google AI StudioおよびVertex AIからパブリックプレビューとして利用できます。
Geminiのモデル階層は「Pro > Flash > Flash-Lite」の3段構成になっています。Proは最高精度、Flashは速度と精度のバランス、Flash-Liteはコストと速度に特化した位置づけです。Gemini 3.0にはFlash-Liteが存在しなかったため、前世代のGemini 2.5 Flash-Liteから直接3.1へのアップグレードとなっている点も特徴的です。
入力はテキスト、画像、音声、動画、PDFに対応しており、コンテキストウィンドウは最大100万トークンです。出力は最大65,536トークンのテキスト生成に対応しています。画像生成や音声生成には対応していないため、これらが必要な場合はFlash以上のモデルを選ぶ必要があります。
ベンチマーク性能とGemini 3.1 Flash-Liteの推論速度
Gemini 3.1 Flash-Liteのベンチマーク結果は、軽量モデルとしては高い水準を示しています。科学知識を測るGPQA Diamondでは86.9%、マルチモーダル推論のMMMU Proでは76.8%を記録しました。コード生成のLiveCodeBenchでは72.0%、多言語QAのMMMLUでは88.9%と、幅広い領域で安定したスコアを残しています。
推論速度の面では、前世代のGemini 2.5 Flashと比較して出力速度が363トークン/秒と約45%向上しています。最初の回答トークンが返るまでの時間も2.5倍速くなりました。リアルタイム性が求められるチャットアプリケーションや、大量のバッチ処理において実用的な改善が期待できます。
Google DeepMindのモデルカードによれば、Gemini 3.1 Flash-Liteは「前世代のより大きなモデルであるGemini 2.5 Flashを、推論とマルチモーダル理解のベンチマークで上回る」とされています。軽量モデルでありながら、前世代のFlash(非Lite)を超える性能を達成している点は注目に値するでしょう。
Gemini 3.1 Flash-Liteの思考レベル制御
Gemini 3.1 Flash-Liteの特徴的な機能として、thinking_level パラメータによる推論の深さの制御があります。Gemini 2.5世代で導入された thinking_budget(トークン数指定)に代わり、3.1世代では minimal・low・medium・high の4段階で思考レベルを設定する方式に変更されました。
この機能は、リクエストの内容に応じてコストと品質のバランスを取るために有効です。定型的な翻訳やデータ抽出には minimal を設定してコストを最小限に抑え、複雑な分析や推論が必要なタスクには high を設定するといった使い分けが可能です。
大量のリクエストを処理する法人環境では、すべてのリクエストに同じ推論深度を適用する必要はありません。用途ごとにthinking_levelを切り替えることで、回答品質を維持しながらAPI利用コストを最適化できます。
Gemini 3.1 Pro では、より高度な推論処理で thinking 機能を活用できます。詳しくは以下の記事をご覧ください。
Gemini 3.1 Flash-Liteの料金体系とモデル比較
Gemini 3.1 Flash-Liteの料金は、Geminiモデルファミリーのなかで最も低価格に設定されています。
モデル | 入力(100万トークンあたり) | 出力(100万トークンあたり) |
|---|---|---|
Gemini 3.1 Flash-Lite | $0.25 | $1.50 |
Gemini 3 Flash | $0.50 | $3.00 |
Gemini 3.1 Pro(20万トークン以下) | $2.00 | $12.00 |
Gemini 2.5 Flash(前世代) | $0.30 | $2.50 |
入力トークンの単価はGemini 3.1 Proの8分の1、Gemini 3 Flashの半額です。バッチAPIを利用すればさらに50%の割引が適用され、入力$0.125/100万トークン、出力$0.75/100万トークンまでコストが下がります。Google AI Studioの無料枠も用意されており、評価段階ではコストをかけずに検証できます。
コンテキストキャッシュにも対応しているため、繰り返し同じ前提情報を送信するワークフローでは、キャッシュの活用でさらにコストを圧縮できるでしょう。
どのモデルを選ぶかは、タスクの複雑さとリクエスト量で判断するのが基本です。高精度な分析や複雑な推論が求められる場合はProが適しています。速度と精度のバランスを重視する一般的な業務利用にはFlashが向いています。一方、翻訳・要約・データ抽出・コンテンツモデレーションなど、パターンが明確で大量に処理するタスクにはFlash-Liteが最もコスト効率の高い選択肢です。
※料金は本記事執筆時点(2026年3月)の情報です。最新の料金はGoogle AI for Developersの料金ページをご確認ください。
法人での活用シーンと選定の考え方
Gemini 3.1 Flash-Liteが力を発揮するのは、大量のリクエストを低コストで処理する必要があるシーンです。Googleの公式ブログでは、大規模な翻訳処理、コンテンツモデレーション、音声の文字起こし、構造化出力によるデータ抽出が主な活用例として挙げられています。
法人での導入を検討する際に注目したいのは、Flash-Liteを単独で使うのではなく、モデルの階層構造を活かしたルーティングの設計です。ユーザーからの問い合わせを最初にFlash-Liteで分類し、定型的な質問にはFlash-Liteがそのまま回答し、複雑な質問のみFlashやProにエスカレーションする構成が考えられます。Googleもこの「インテリジェントなリクエストルーティング」を推奨用途として明記しています。

一方で、Flash-Liteには不向きなタスクもあります。100万トークンの長文コンテキストからの精密な情報検索(MRCR v2ベンチマークで12.3%)は弱点です。画像生成・音声生成・Gemini Live APIにも非対応のため、マルチモーダル出力が必要な用途ではFlash以上のモデルが必要です。
弊社の経験から言えば、AIチャットボットの運用では「全リクエストの7〜8割は定型的な問い合わせ」というケースが多く見られます。この大半をFlash-Liteで処理し、残りの複雑な質問のみ上位モデルに回す設計にすれば、全体のAPI利用コストを大幅に削減できる可能性があります。ただし、ルーティングの精度自体がサービス品質に直結するため、分類ロジックの検証は慎重に行うことをお勧めします。
まとめ
Gemini 3.1 Flash-Liteは、前世代のGemini 2.5 Flashを上回る推論性能を、半額以下のコストと45%高速な推論速度で実現した軽量モデルです。thinking_levelパラメータによるコストと品質のバランス制御や、バッチAPIの50%割引など、大量リクエスト向けの仕組みが充実しています。
すべてのリクエストを高性能モデルで処理する必要はありません。タスクの複雑さに応じてPro・Flash・Flash-Liteを使い分けるモデルルーティングの設計が、API利用コストの最適化において重要な考え方になるでしょう。
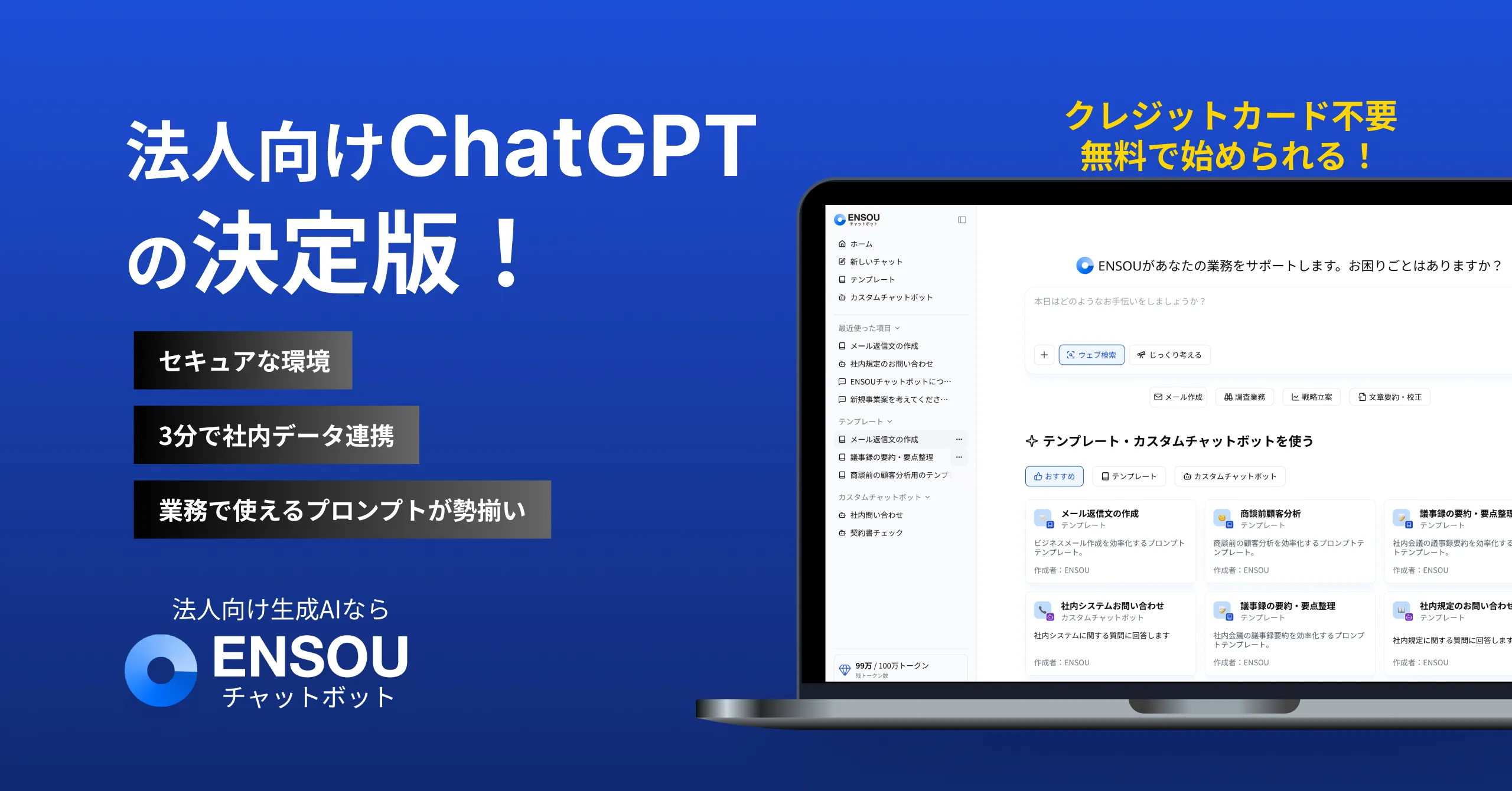
組織で生成AIを導入するならENSOU AI
株式会社Digeon では法人向けAIエージェントのファーストステップに最適なサービスである「ENSOU AI」を提供しています。
無料ですぐに使えるフリープランのご利用開始はこちらから👇
サービス紹介資料をこちらからダウンロードいただけます👇
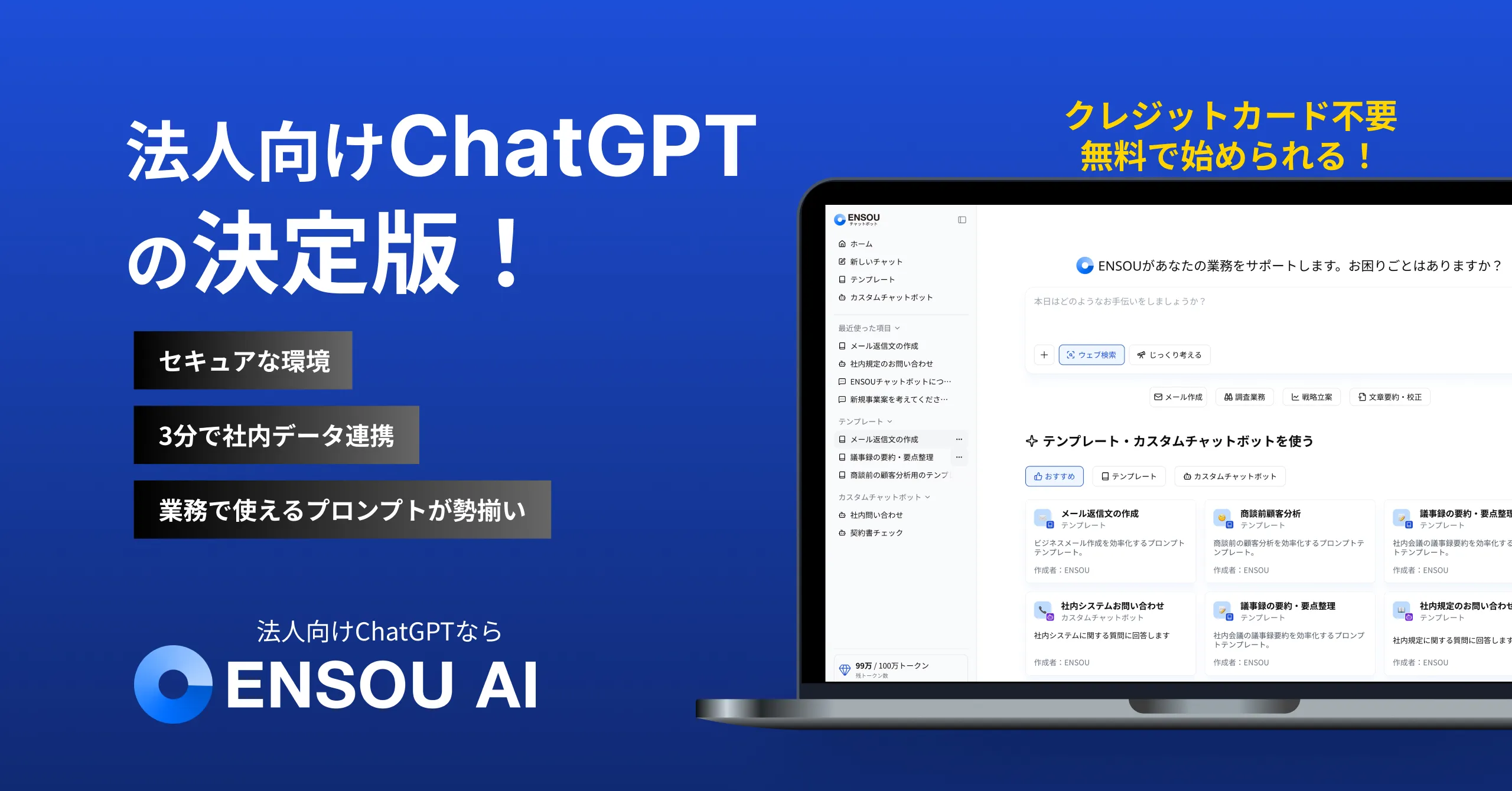
ご相談、無料トライアルは、以下からお問い合わせください👇
あわせて読む
NEW
最新記事
ブログ
Gemini 3.1 Flash-Liteとは?性能・料金を解説

ブログ
GitHub Copilot CLIとは?機能・料金・使い方
.png)
ブログ
Gemini 3.1 Pro が登場 : 推論能力とコーディング能力が大幅に向上

ブログ
Excelファイル作成比較! CopilotChat vs ENSOU AI

ブログ
Claude Sonnet 4.6 がリリース : 実務で使えるほど優秀なのか実力検証!!

ブログ